编码规则
五笔字形的编码是按汉字书写顺序,以基本字根为单位、再按一定的编码规则给出的,编码长度最多为四码(即四个字母)。
五笔字形规定,单个汉字可分为三类:键名汉字(共25个)、成字字根汉字(即一个汉字本身就是一个基本字根,不包括键名字)键外字(即必须拆分为两个或两个以上字根的汉字)。下面分别介绍这三类汉字的编码规则。
前面介绍了键盘上A~Y共25个键位,分别在键上各字根中取一个字根作为其键名字,它们的编码是把所在键的字母连写四次,输入它们时需连敲四下。 例如: “王”字的编码为:GGGG,输入时需连敲G键四下。 键名字共有25个:
王(G) 土(F)大(D) 木(S) 工(A)
目(H) 日(J)口(K) 田(L) 山(M)
禾(T) 白(R)月(E) 人(W)金(Q)
言(Y) 立(U)水(I) 火(O) 之(P)
已(N) 子(B)女(V)又(C) 纟(X)
在130多个基本字根中,除25个键名字根外,还有几十个基本字根本身也是汉字,如“八、用、西、石”等,在五笔字形方案中,称它们为成字字根。成字字根汉字的编码规则为:键名码+首笔码+次笔码+末笔码
其中,键名码即该汉字字根所在键的字母;首笔码、次笔码和末笔码不是按字根取码,而是按单笔画取码,横、竖、撇、捺、折五种单笔画取各区第一字母,即:横(G)、竖(H)、撇(T)、捺(Y)和折(N)。当成字字根仅为两笔时,只有三码,则补上空格键作为编码的结束。例如:汉字“古”所在键名D,首笔画为“一”,次笔画为“丨”,末笔画为“一”,因此,汉字“古”的编码为DGHG。
其中,五个单笔画字的打法固定为(所在键 * 2 + LL),即打两次所在键加两个L,即: ggll 一(横); hhll 丨(竖); ttll 丿(撇); yyll 丶(捺); nnll 乙 (折)
一 ∶11 11 24 24 (GGLL)
丨 ∶21 21 24 24 (HHLL)
丿 ∶31 31 24 24 (TTLL)
丶 ∶41 41 24 24 (YYLL)
乙 ∶51 51 24 24 (NNLL)
凡是键外字,首先必须按其书写顺序拆分为基本字根。 凡由四个或超过四个字根构成的键外字,均取其第一、二、三、末四个字根码组成它的输入码。例如:
汉字“酸”,拆分为:西 一 厶 夂,编码为SGCT;
汉字“熊”,拆分为:厶 月 匕 灬,编码为CEXO。
凡由不足四个字根构成的键外字,在依次敲入其字根码后,再补一个识别码,以补足四码(如果仍不足四码,再补一个空格键)。
一个汉字的识别码是由该汉字的末笔笔画信息和字形信息结合组成,也称末笔字形交叉识别码。汉字的识别码如下表所示:
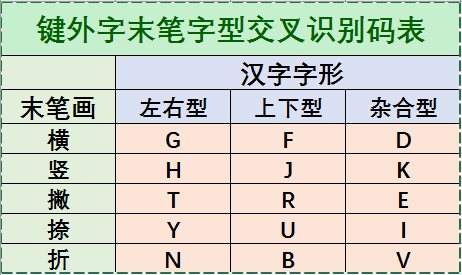
在一个汉字拆出的字根不足四个,其码长不够四码的情况下,为什么五笔字形编码方案不是简单地补一个空格结束,而是引进末笔字型交叉识别呢?我们通过一些示例来说明这个问题。
例如,汉字“沐、汀、洒”的字根编码均为IS,这三个汉字均为左右型汉字,但“沐”的末笔画为捺、“汀”的末笔画为竖、“洒”的末笔画为横;汉字“什、仁、付”的字根编码均为WF,这三个汉字都为左右型汉字,但“什”的末笔画为竖、“仁”的末笔画为横、“付”的末笔画为捺;汉字“叭、只”的字根编码均为KW,这两个汉字的末笔画均为捺,但“叭”为左右型汉字,而“只”为上下型汉字。
这样的例子还可以举出许多,由此看出,字根不足四个的汉字,拆出的字根编码重码率较高,如果只简单地补一个空格键结束,这些汉字都可能成为重码汉字;但另外一方面,对于字根编码完全相同的汉字,其末笔画及字形也完全相同的可能性则大大减少。所以,字根不足四个的汉字编码在补上识别码后,可用它来区别可能重码的那些汉字,取到消除重码的目的。末笔字交叉识别码就是在这种考虑下提出来的。
例如,汉字“沐”的字根编码为IS,末笔画为捺、左右型汉字,识别码为Y,其五笔字形编码为ISY:同样,“汀”的五笔字形编码为ISH,“洒”的五笔字形编码为ISG。
需要说明的是,关于末笔画,在特殊情况下有如下规定:
⑴包围型汉字中的末笔,规定取被包围部分的末笔。如“国”字的末笔取“丶”。
⑵对于有走之底的汉字,不以走之作为末笔,规定以去掉走之部分后的末笔作为整字的末笔。如“逞”的末笔取横。
⑶末字根为“刀、九、匕、力、乃”时,一律规定末笔画为折。如“化”的末笔取折。
⑷“我、线、成”等汉字的末笔一律取撇去点。

