识别码
为达到减少重码的目的,引入了“末笔字型交叉识别码”的概念,简称“识别码”。 当一个非单字根汉字拆分不够4个字根时,才需要追加识别码。
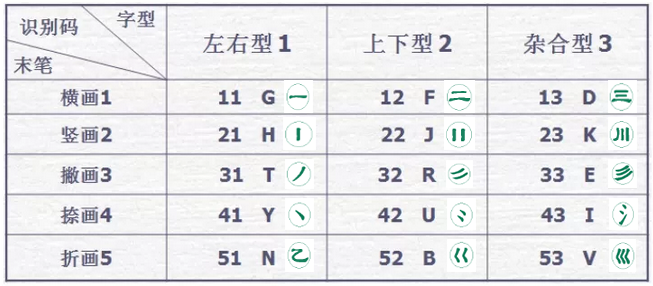
五笔识别码是将汉字的最后一笔画(不是最后一个字根)所在的区(横1、竖2、撇3、捺4、折5、)中 ,位号等于该字字型号(左右型1、上下型2、杂合型3)的键。 即末笔决定识别码所在的区号, 字型决定识别码所在区的位号;横至折的区号分别为1至5;左右、上下、杂合型决定的位号分别为1至3。
比如“备”字编码为“tlf”,即识别码为“12”的“f”键,其最后一笔为横,说明该字的识别码在横区(区号为1) ,字型是“上下型”,“上下型”是“2”的位号,所以它的识别码组成为:末笔为横“1”+上下型“2”=“12”键,即“f”键。 如下图:
1,只有小于四个字根的单字才需要加识别码。
即成字根字(先打它所在的键,再按书写顺序打它的第一笔、第二笔和最后一笔)、键名字(连续击它所在的键四下),都不需要加识别码,或者一个汉字如果拆出了四个以上的字根,如“我”(丿,扌,乙,丶,丿)、“寒”(宀、二,刂、一,八,丶丶),就不再需要加识别码。
2,单笔划(一,丨,丿,丶,乙)与其它字根相交、相连时都应该把该字看成是杂合结构。
如:“乏”,拆分字根为:丿、之,但由于单笔划“丿”与“之”字相连,所以它必须看成是杂合结构,从而确定识别码为“I" 再如:”乡“,拆分字根为:纟(须去掉最后一提)、丿,但由于单笔划“丿”与“纟”相连,也必须看成是杂合结构,从而确定它的识别码为“E”
但如果单笔划与字根既不相连也不相交,就必须正常看待。 如:“旦”,上下结构; “旧”,左右结构。
3,字根与字根相连,是上下结构;字根与字根相交,杂合结构。
如:“看、着”,上下结构;而“击、出、里”为杂合结构。
4,带“辶、廴、囗”等全包围、半包围结构的汉字,它们的末笔必须取被包围结构的最后一笔,而不是这些偏傍的末笔。此举是为了提高识别码的效率,减少重码率。
如:连(LPK)、圆(LKMI)
5,若“刀、九、匕、力、乃”在参与识别码,作为汉字的最后一个字根时,其末笔统一规定为“乙”(折)。
注意:当“刀”字作为成字字根时,末笔为“丿”(撇),编码为vnt。
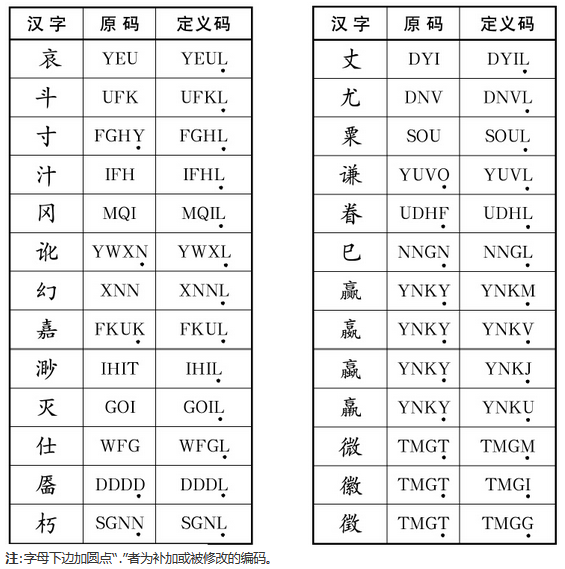
容错码是:“容易”编错,但“容许”编错的码。容错码的设置,是为了照顾不同的取码习惯, 使他们用容易编错的码,照样可以打出所要的字来。“容错码”主要有三种类型: 编码容错、字型容错、 定义后缀。但实事上由于容错码打破了编码的唯一性,使人难以辨认正确的编码,是最终提高速度的障碍, 所以很多五笔软件的码表中都去掉了容错码,只保留正确的、唯一的编码。
编码容错:个别汉字的书写笔顺因人而异,致使字根的拆分序列也不尽相同,因而容易弄错。 如“长” 有多种笔顺:1)TAYI(正确码), 2)ATYI(容错码), 3)TGNY(容错码), 4)GNTY(容错码)
字型容错:个别汉字的字型分类不易确定,如“占”字:1)HKF(上下型,正确码), 2)HKD(杂合型,容错码)
定义后缀:为了进一步减少甚至杜绝重码,人为地将一些重码字的最后1个码或2个码修改为L(24),或改为有识别能力的字根的做法,叫“定义后缀”。 例如:“喜”与“嘉”重码,输入码都是FKUK。因为“喜”更常用,输入后显示在提示行的第一位,可以默认上屏,相当于不重码,等于“独享”原来的编码FKUK;为了使“嘉”在保留原来编码的同时,也能够“一步到位”上屏,就将最后一码K改为L,使“嘉”也可“独享”一个编码FKUL,这样输入FKUL就只出来“嘉”一个字了。
为什么要改为L而不用别的键呢?是因为以L为最后一码的编码空间冗余太大,又因为L键用右手无名指击键灵活方便。 这些常见重码字的“人工修正码”请见下表: